You might have missed it, but the big data visualization research conference happened online at the end of October!
IEEE VIS 2021 was held online, virtually, on https://virtual.ieeevis.org. Before you read this recap, you should check out some of the other reviews that have been posted: the Data Visualization Society’s Nightingale journal had a review and the SIGGRAPH blog also had a review. Let me know if you know of others!
Like last year, this summary (in contrast to the others) is more focused toward the interests of an industry observer. Specifically, I’m targeting this summary toward my product team (Power BI at Microsoft), and separating it out by the core audience for the research. This is in contrast to splitting it up by product discipline last year… let me know on Twitter if this works for others as well. 😊
Jump to the appropriate section:
- Presenting visualizations
- Finding visualizations
- Visualization design
- Accessibility
- Natural language
- Explainable AI
- Other workshops (+ things to chew on!)
For each item of work I call out, I try to link to the presentation (YouTube direct link), the paper and associated materials if I find an open-access version, the DOI (when I get around to it!), and the “landing” page as it appears on the virtual conference website.
If you’re interested in learning more about the work, you should watch the paper’s presentation (usually around 15 minutes), then the paper if you want more detail. You can access papers behind the IEEE paywall by using your institutional credentials—for Microsoft employees, use aka.ms/mslibrary/ieee.
Let me be clear, this is not a comprehensive overview of IEEE VIS 2021! I’m just pulling out what I think would be relevant to industry professionals that may not otherwise attend VIS. If this stuff is interesting to you, we would love to have you attend VIS next year – ask me if you have any questions. I finalized my five-year volunteer stint as one of the IEEE VIS web chairs recently 😉
Presenting visualizations

In contrast to previous years, there was much more interest in how to effectively present visualizations to audiences that don’t normally consume visualizations or who may not be acquainted with the domain of the data displayed.
Robert Kosara and Matthew Brehmer from Tableau Research conducted a series of prototype interview studies with people in organizations that regularly presented visualization-focused reports to a (captive) audience in their TVCG paper (presentation, paper, landing). The designs explored interfaces for small-group interactive explorations, using a “presenter-view” similar to PowerPoint’s “presenter view” to house filter/slice controls to declutter the interface, or integration of presenter video in a recorded presentation. This study yielded quite interesting reactions from study participants, with both concerns and excitement about the potential for the new modalities, yet concern that they could also be interpreted as flash with no substance behind them.
Moving toward novices authoring visualizations, a team from Microsoft Research Asia created a working prototype to allow PowerPoint authors to augment and update static infographics used in reports (presentation, paper, landing). They make this possible by automatically understanding how labels, sizes of shapes, and icons work together to make a loose specification, thereby allowing data updates. This is a really neat example of lowering the barrier for entry to creating bespoke visualizations, where authors can use tools they’re already familiar with (e.g., PowerPoint drawing tools) to make data-driven visualizations.
Authors trying to create visualizations may take advantage of systems that recommend visualizations to them. However, the manner in which they are recommended may quickly overwhelm the author, leading to choices that may not match the intentions of the author. In “Deconstructing Categorization in Visualization Recommendation: A Taxonomy and Comparative Study”, the team looked at what recommendations can be made for choosing between visualizations and their designs (presentation, paper, landing). They making the distinction of categorizing the recommendations based on the type of transformation done. One might hope that all you’d have to do from this point would be to also ask the author what their analysis tasks were and you’d end up with a perfect visualization!

Somewhat similar, the presented Kori system (shown above) provides a interface to provide tighter coupling between visualization features and the text that describes them (presentation, paper, landing). The mixed-initiative system combines authoring and viewing interfaces, allowing authors to link to particular data points or groups of data points to describe them in more detail.
A little more meta-academic, Evanthia Dimara and John Stasko ask the question where “decision making tasks hide”? (presentation, paper, landing) The typology of analysis task is a funny quirk of trying to understand what people actually do with visualizations, and many of the canonical tasks miss a core task at the center of BI: decision making. “Should I do something?” Other fields have tackled this, namely business literature, but the focus of this paper makes the connection to how visualization design can help to elucidate connections that may not otherwise be apparent. This work strikes at the core tenent of how visualizations lead to insight (and thereby action), and is worth a deep read.
Finding visualizations

In our information-laden world, we’re now getting hit over the head with visualizations. Like the multitude of text in the world, there needs to be better ways to find and access visualizations that are relevant for our interests or responsibilities. A team from UBC looks at this problem through their system “VizSnippets”, which presents visualization bundles into representative previews (presentation, paper, landing). The authors propose a set of eight challenges that these Twitter-like thumbnails should support, and describe how the structured content of a BI report or dashboard could be leveraged to provide automated, succinct summarization of a report or dashboard’s contents.
Visualization design
There’s a lot to speak on here, so I tried to further partition relevant design work into four areas: individual visualization, groups of visualizations, design for viewer understanding, and visualization engineering.
Individual visualizations

Caitlyn McColeman and co-authors at Northwestern University look at the classic ranks raking of visual channels in a new light, teasing appart differences when the target task and number of items to compare changes (presentation, paper, landing). The result is a comprehensive user-study that holistically ranks visual channels (such as length, angle, and color luminance) – leading to some interesting insights when the number of relevant visual marks increased. This study appears to set a standard for follow-up work to understand how visual channels combinatorially perform on different tasks and with different data characteristics.
Greg Woodin and co-authors present a paper that examines the relationship between the conceptual metaphor (up is good) and convention (y-axis value goes up): (presentation, paper, landing). They gain insipriation from line charts describing gun deaths where the line goes down when more deaths are caused. Inspecting how the convention of axis ordering and semantic valence correlates, they come to the surprising conclusion from their study that the effects from inverting the value (y-) axis are more strongly negative than trying to align to the valence direction. This manuscript is definitely worth a closer look!
Often in visualization construction, it can be difficult to distinguish differences between marks that represent different data items. To help elucidate this “just-noticable difference” in visualization marks, Min Lu and co-authors describe a linear mixed effects model informed by a user study that looks at “intensity” of visual marks and their distances (presentation, paper, landing). They describe how this model could help to emphasize how potential comparisons between marks of interest can be subsequently emphasized.
Groups of visualizations
When it comes to groups of visualizations, research starts to concentrate on comparisons across visualizations or better ways to ensure consistency across visualization.

Cindy Xiong and co-authors present their work on how arranging the categories and series in column charts in different ways can affect the types of comparison takeaways viewers make (presentation, paper, landing). Generally, such a decision is left to the visualization author, but this paper takes a laser-focused approach to understanding how stacking, clustering, and juxtaposing affects snap comparisons. Theirw conclusions has ramifications of how authors should pick between layouts to communicate the judgments they want prioritized.
Yngve Kristiansen and colleagues at the University of Bergen demonstrate their system for “semantic snapping”, which resolves inconsistencies between a pair of visualizations (presentation, paper, landing). Similar to the dashboard inconsistencies paper presented several years ago, this work goes further and brings real-time interaction into the picture. They operationalize multi-view visualization tennt of consistency between visualizations (color scales, axis scales, etc.), while also striving to remove redundancy in information conveyed. Pretty slick!
Design for understanding
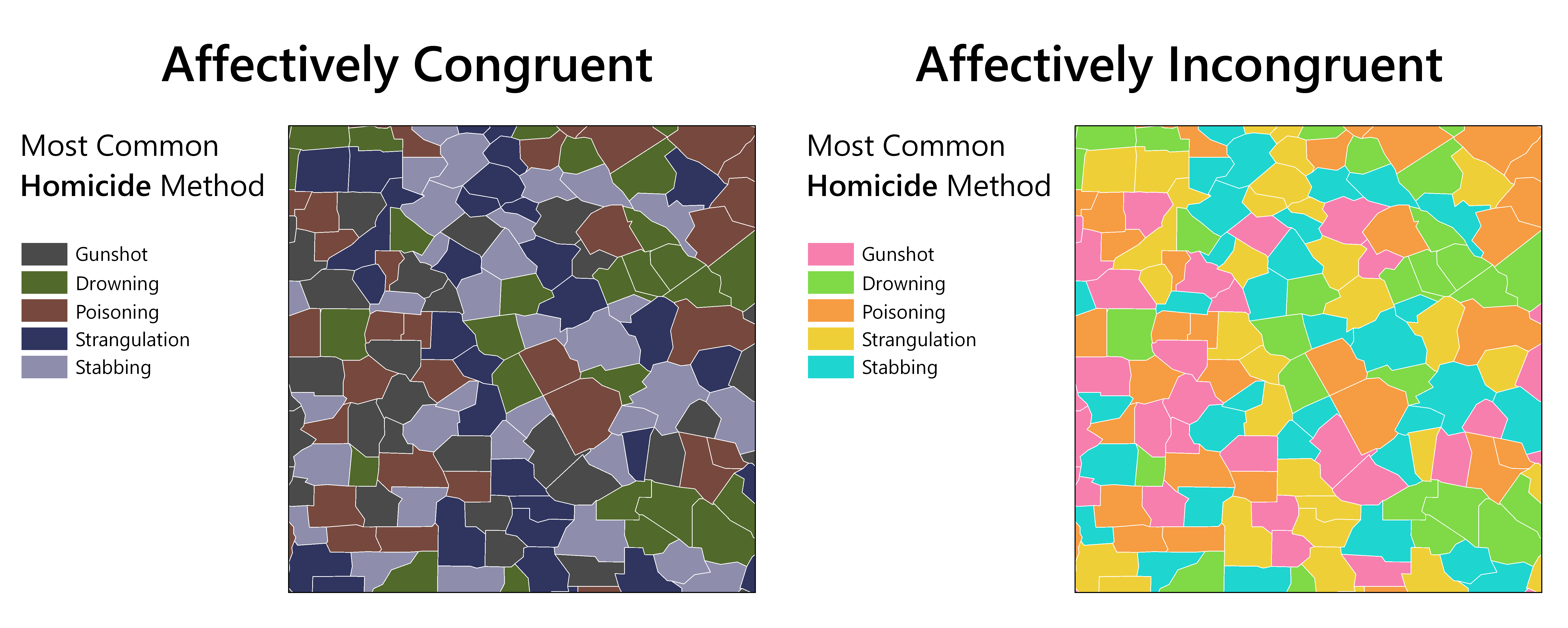
Cary Anderson and Anthony Robinson presented their work on affective congruence of colors in visualization (presentation, paper, landing). They focused on cartogram visuals, and asked the question of how color choices affects both objective and subjective interpretation of visualizations dealing with data in different domains, such as a bright color palette dealing with cancer statistics. For visualizations that appeared “bright” but dealt with “dark” topics, these “incongruent” visualizations could cause confusion in subjective interpretations, though a strong affect was not found for objective interpretation. The authors provide several suggestions for supplying the appropriate context around thematic maps, hopefully leading to more congruent visualizations.
Smiti Kaul and co-authors present their work on improving visualization interpretation with counterfactuals (presentation, paper, landing). They add to the recent body of work of exploratory visualization, where viewers take a tour through the space of multi-dimensional visualization to understand the makeup of their data. However, instead of taking the procedural generation of visualizations that others have taken, they take a more adversarial view: counterfactuals! Given a visualization of interest, they can generate a visualization specification on the dataset that may show something surprising or antithetical in comparison to the reference visualization. In this way, the authors posit that they can help to alleviate the risk of bias and help viewers understand underexplored descriptions of their dataset.
Visualization development
Scalable SVG (SSVG) is a technique developed by researchers at Brown and Northeastern University to render SVG specifications to virtual DOM, thereby saving browsers from having to manage fast-changing DOM nodes and properties (presentation, paper, landing). The SSVG library essentially becomes a translation layer between constructed DOM and a virtual DOM layer that gets eventually rendered with WebGL, resulting in performance improvements 3-9x. The best part?—event binding still works! Check it out at https://ssvg.io/.
Accessibility
Accessibility should be top-of-mind when it comes to authoring visualizations, and the following works help to elucidate how best to support viewers. This is especially poignant, as one of the works below note that 0% of the papers submitted to VIS in the last 5 years had alt-text specified in their figures. “alt-text” is short-hand for “alternative text”, a textual descriptions read out by screen reader applications used by people with reduced vision.
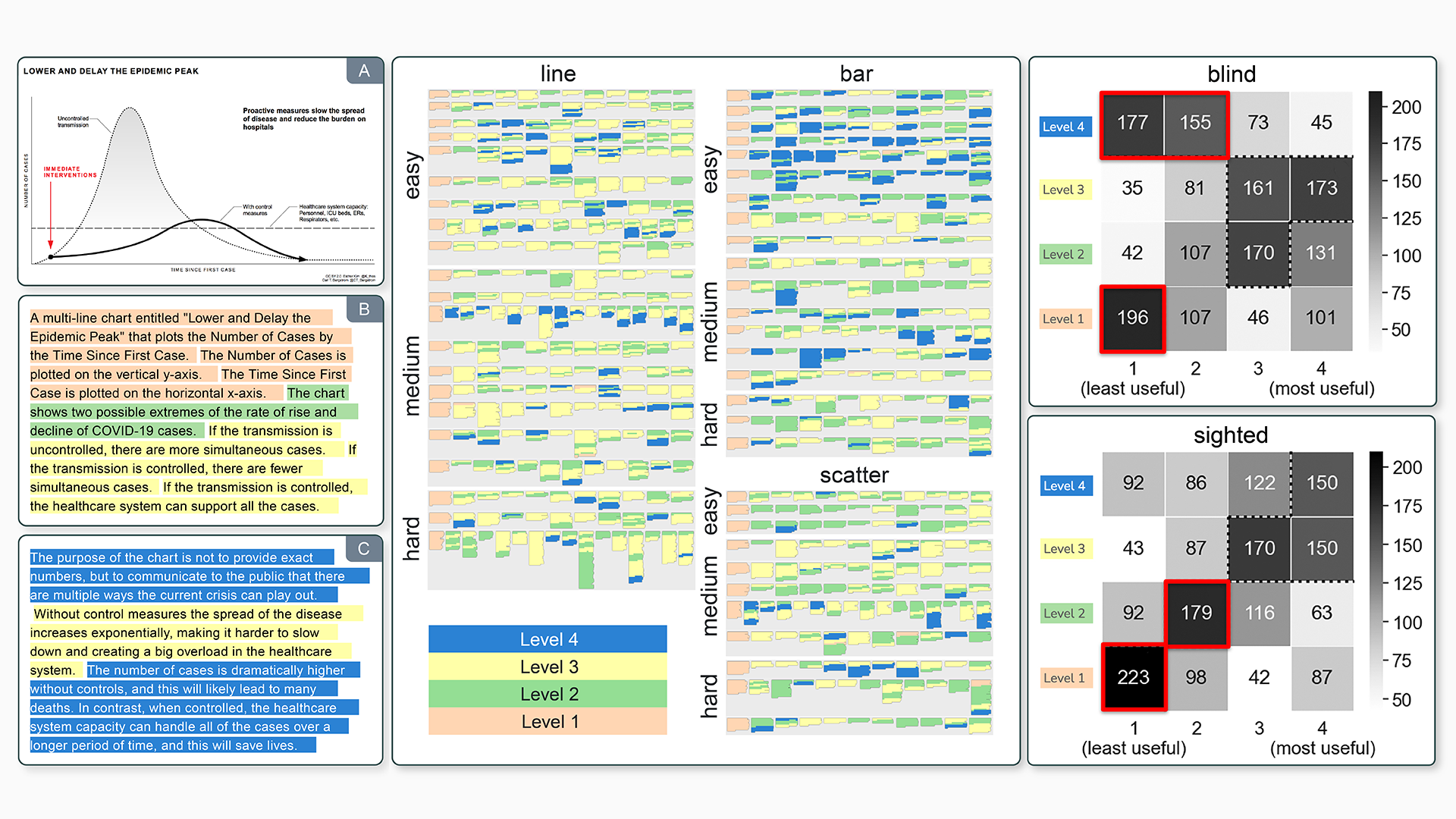
It can be a difficult task to try and decide what kind of description to provide as alt-text for a visual. Alan Lundgard and Arvind Satyanarayan at MIT describe an exploratory study where they break up textual descriptions into four levels, then ask non-sighted and sighted viewers what they think of those descriptions (presentation, paper, landing). What they find is a little surprising; sighted viewers appreciated higher-level descriptions of visualizations, bringing in context not displayed in visualizations, whereas non-sighted viewers saw the extra commentary as anthetical to the “bare” nature of visualization without commentary. However, there was a significant difference of opinion between individuals, pointing towards providing agency for users to explore different “levels” of descriptions.
Starting instead with a generative model, Crescentia Jung and co-authors at the University of Wisconsin-Madison set out to answer the question of what viewers want out of alt-text (presentation, paper, landing). They start by surveying the state-of-the-art, and quickly find that IEEE VIS/TVCG has a glorious [sic] track record of 0% alt-text support. They expand their search to the ACM SIGCHI and ASSETS conference as well as notable journalism examples, collect pairs of images + alt-text, then categorize them through an open-coding process. Differently than the previously-described paper, they break out into four categories: brief description, detailed description, data trends, and data point information. Through a semi-structured interview process, they provide different types of alt-text and ask the viewer for refinement. They provide several recommendations based on the study and their analysis for more accessible visualization, including making a hidden data table available.
Natural language
There was a significant amount of natural language research presented at the conference, though I was not able to attend many talks. There was a workshop named NL VIZ early in the conference looking at merging natural language techniques with visualization tasks, quite relevant for the BI landscape.
Hendrik Strobelt and co-authors presented the GenNI system that supports data-text generation from tables (presentation, paper, landing). While it works by example, the system allows a model builder to quickly try out different rulesets in a visual, no-code manner, and resolve potential issues with additional rules. This system could be implemented in conjunction with a strong visualization grammar to help redundantly encode information in visualization and textual description.
Explainable AI
Again, I wasn’t able to attend many talks here, but there were several opportunities to learn more about this at the conference. The VIS full papers session on Explanable AI and Machine Learning should be relevant, as well as the VISxAI associated event and Visual Data Science (VDS) associated event.
Other workshops
There were several other workshops, many of which involved real-time discussions with other researchers. I wasn’t able to be in multiple places at once, but this is a sample of what I caught!
The workshop on Audio-Visual Analytics discussed different manners of sonification for data, and how people interpreted different tones and combinations of sounds in conjunction with consuming visualizations. The study in this subfield is relatively new, so much of the discussion revolved around how to support authoring tools, differences in design of sonification to represent different data characteristics communicated by visualization, and general awareness.
The alt.vis workshop simulates the alt.chi model to capture work that isn’t typically presented at the conference. The result is a wonderful mix of high-impact work covering theories such as “bullshit visualization”, designing visualizations for harm, knitting visualizations, and touching visualizations as an emotive experience.
Somewhat less tougne-in-cheek, the VIS Arts Program: DIS/CONNECTED hosted many inspiring data visualization / art presentations. This is definitely worth a perusal as well as an exploration of artists’ statements as presented in the conference (session 1, session 2).
The Visualization for Social Good workshop is also worth looking through, though I was not able to attend live. I was especially taken by the work presented by Alyxander Burns and co-authors at UMass Amherst where they looked at the importance of providing metadata along with visualized data (paper). They categorize different types of metadata (e.g., provenance, processing, encoding, people), and describe the trade-offs in providing this information to the viewer. They describe potential future steps to better integrate this necessary metadata in a presentation system.
In summary
There is too much material from an IEEE VIS conference to cover in detail in a single blog post. If you are interested in this material further, I suggest you pursue the other summaries and recaps linked in the beginning of this post.
All the presentations are available on the virtual IEEE VIS 2021 website, along with DOIs for the original documents.
Acknowledgements
We consider the images used in this recap as fair use under US Copyright law (17 U.S. Code § 107) for the purpose of reporting and commentary. No images are lifted from official IEEE sources or finalized, published materials.
If you determine that there is an exception, please contact the author.