There’s been a lot of activity about IEEE VIS in the last month. You should check out some of the other reviews that have been posted: Data Stories had their VIS 2020 review, the PolicyViz podcast talks through some highlights and the Data Visualization Society’s Nightingale journal had a review as well.
This summary (in contrast to the others) is more focused toward the interests of an industry observer. Specifically, I’m targeting this summary toward my product team (Power BI at Microsoft), and separating it out by discipline. Let me know on Twitter if this works for others as well. 😊
Jump to the appropriate section:
For each work I call out, I try to link to the presentation (YouTube direct link), the paper and associated materials if I find an open-access version, and the “landing” page as it appears on the conference website for that work.
(Let me be clear that this isn’t a comprehensive overview of IEEE VIS 2020! There are seven parallel tracks, so please keep in mind that this recap is biased toward the events I was able to catch live as they happened. Nearly all presentations/events are available on the virtual IEEE VIS 2020 website.)
For practitioners
There were a number of associated events targeting the visualization practitioner. Although I was not able to attend Vis in Practice program or Visual Data Science program, you should definitely check those out. Those events typically focus on practitioners’ experiences utilizing visualization for their problem domain, skewed toward scientific data.
The VisComm workshop (Visualization for Communication) had a number of good papers, I’d suggest you check out the program. In particular, I enjoyed François Lévesque’s presentation describing how taxes, benefits, and public spending change over time for an individual (presentation, paper, landing). They took a very difficult problem to solve (how do you use visualizations to communicate tax benefits/liabilities to the general public), and walk through their thought and design process. Check out their work online: Life stories.
Color

Danielle Szafir, Francesca Samsel, and Karen Schloss presented a tutorial on the theory and application of color tools and strategies for using color effectively in visualizations. In particular, Danielle talked through a set of color tools using an Observable notebook, taking tools such as Color Crafter (for logo color-focused color ramps) and Colorgorical (generating color palettes). While many other tools exist, this notebook is an extremely practical playground for rapidly prototyping a strong color palette that imbues brand identity.
Design
The entire full paper session of guidelines and design spaces is a great place for people interested in visualization design. A lot of it is pretty theoretical, however, and serves to organize future user research. As an example, Alex Bigelow presents his team’s work on organizing data abstractions for visualization (presentation, paper, landing). They identify 24 codes that drive four themes, and they very quickly find that data abstractions, while a convenient to organize how data is utilized, is interpreted differently by different people. Such an avenue would be quite interesting to explore further, especially in evaluating a business’ “data culture.”
In the intelligent systems session, Shayan Monadjemi presented their group’s efforts to infer exploration patterns and adapt visualizations to suit the user (presentation, paper, landing). Their exploration is very neat and demonstrates how Bayesian modeling can help to slightly modify what a visualization shows just based on the interaction patterns. One could imagine extending this model to someone browsing a dashboard!
Danqing Shi presents their work on supporting the automatic generation of a visual data story from a spreadsheet (presentation, paper, landing). They define some key phrases, tie those phrases to features in the data, and weight those features according to their “reward”: how surprising are these facts? While such a system would help start a data story, a system in practice would almost certainly require author intervention and guidance.
Content
Michael Oppermann presented “VizCommender”, a system to find related content in a library of dashboards and associated visualizations (presentation, paper, landing). Working off of text stored in the contracts in the reports, the system suggests related reports or dashboards by matching to a target workbook. While the system targets Tableau workbooks in a library, concepts learned in this work can be abstracted for use in other “big data report” content libraries to find content relevant for a user’s interests.
For developers
In this section, I’ll concentrate on work presented during the conference that has more immediate applicability to be used by visualization developers or report/dashboard authors.
I really enjoyed my time moderating the short paper session on systems, libraries, and algorithms. In that session, there were a number of immediately application techniques and libraries that can be used. Rene Cutura presented their dimensionality reduction JavaScript library (DruidJS), which focuses on DR implementations that can be immediately visualized (presentation, paper, code library, landing). I strongly encourage you to check out their presentation; there is a very convincing live demo that shows the capability of the library.
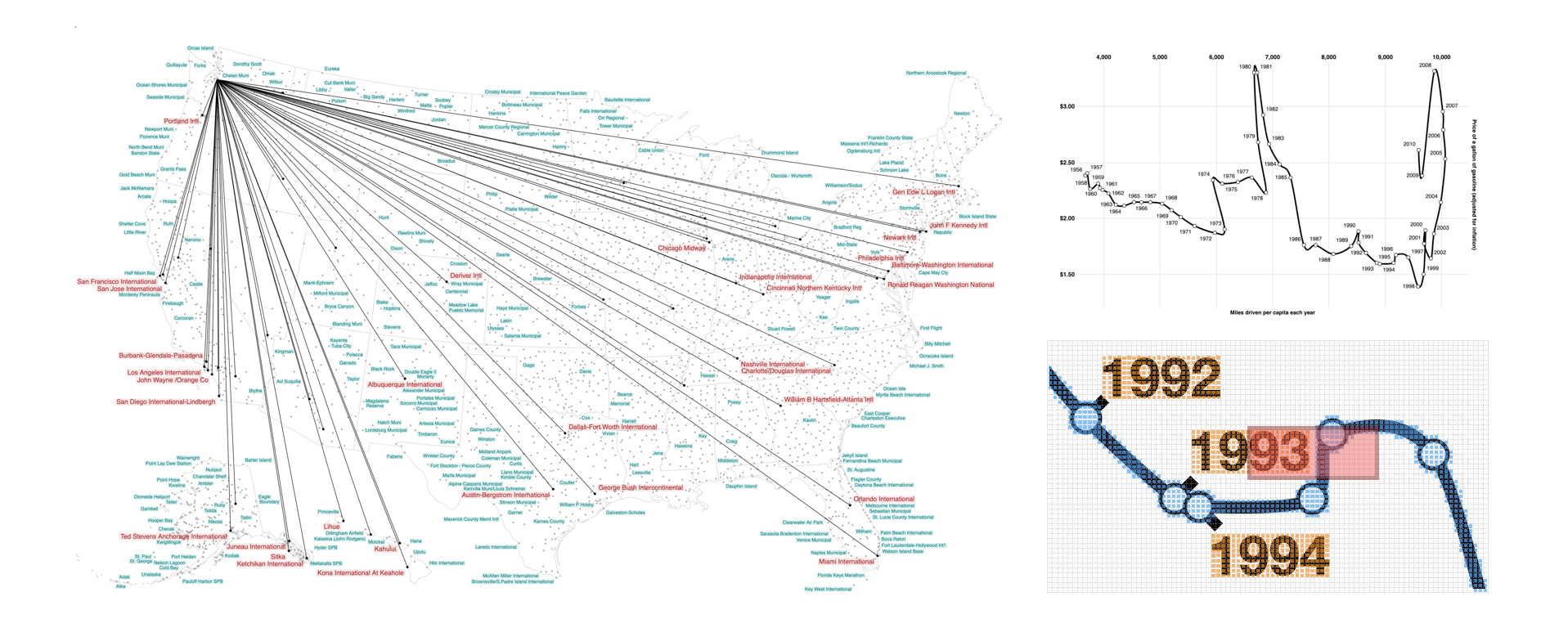
Chanwut Kittivorawong presented a technique for a raster-based implementation for placing data labels on a visualization (pictured above; presentation and paper). Their technique is space-aware, deterministic, naturally supports precedence ordering, and is extremely quick.
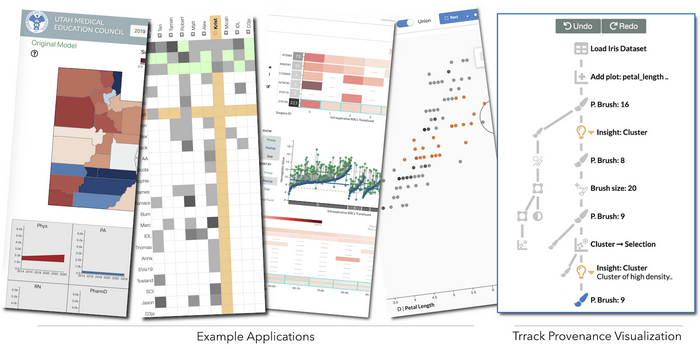
Zach Cutler presented “Trrack” (pictured above), an implementation of a provenance tracker in an interactive data system (presentation, paper, tool, landing). They present an library that implements a generalized, hybrid approach between state-based and action-based undo/redo stacks.
“Encodable” is a visualization technique presented by Krist Wongsuphasawat that takes the “adapter” design pattern to an extreme for data visualization libraries presentation, (paper, code, landing). This library helps to determine a visualization grammar-defined interface to help disjoint visualization libraries talk to one another. Given a visualization specification and a host of libraries and their encoding specification, Encodable simplifies the process of cross-talk between the libraries and promotes usage of disparate visualization libraries.
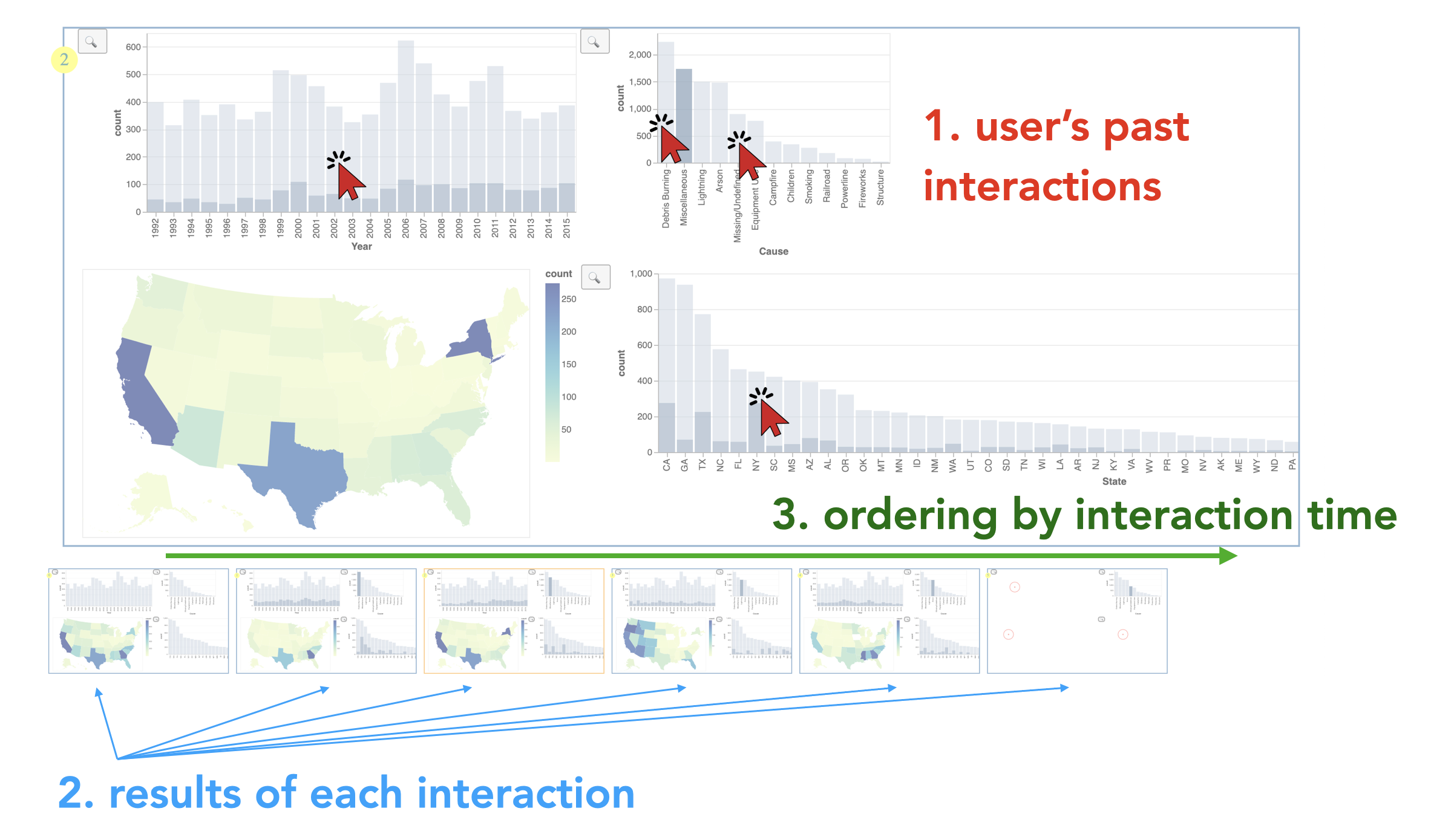
“Interaction Snapshots” was a neat technique presented by Yifan Wu that attempts to address issues of high-latency queries that drive data visualizations (pictured above; presentation, paper, landing). The technique is an in-between in reducing latency on the backend system serving the data and promotion of techniques such as progressive data analytics that start with a low-fidelity visualization (at high levels of aggregation or error) and progressively increase fidelity. By staggering visualization results, they show that their technique can minimize the latency felt by viewers interacting with a high-latency data source.
Rupayan Neogy presented their work of summarizing the methods of representing multi-user interactions with visualizations (presentation, paper, landing). They use specificity and situatedness to guide their exploration of the space, and, in doing so, propose different methods of representing multi-user interactions and the trade-offs between those represntations. This paper provides a lot of ground-work for supporting real-time interactions, and start to determine a workflow for supporting a whole host of interaction types and visualization state.
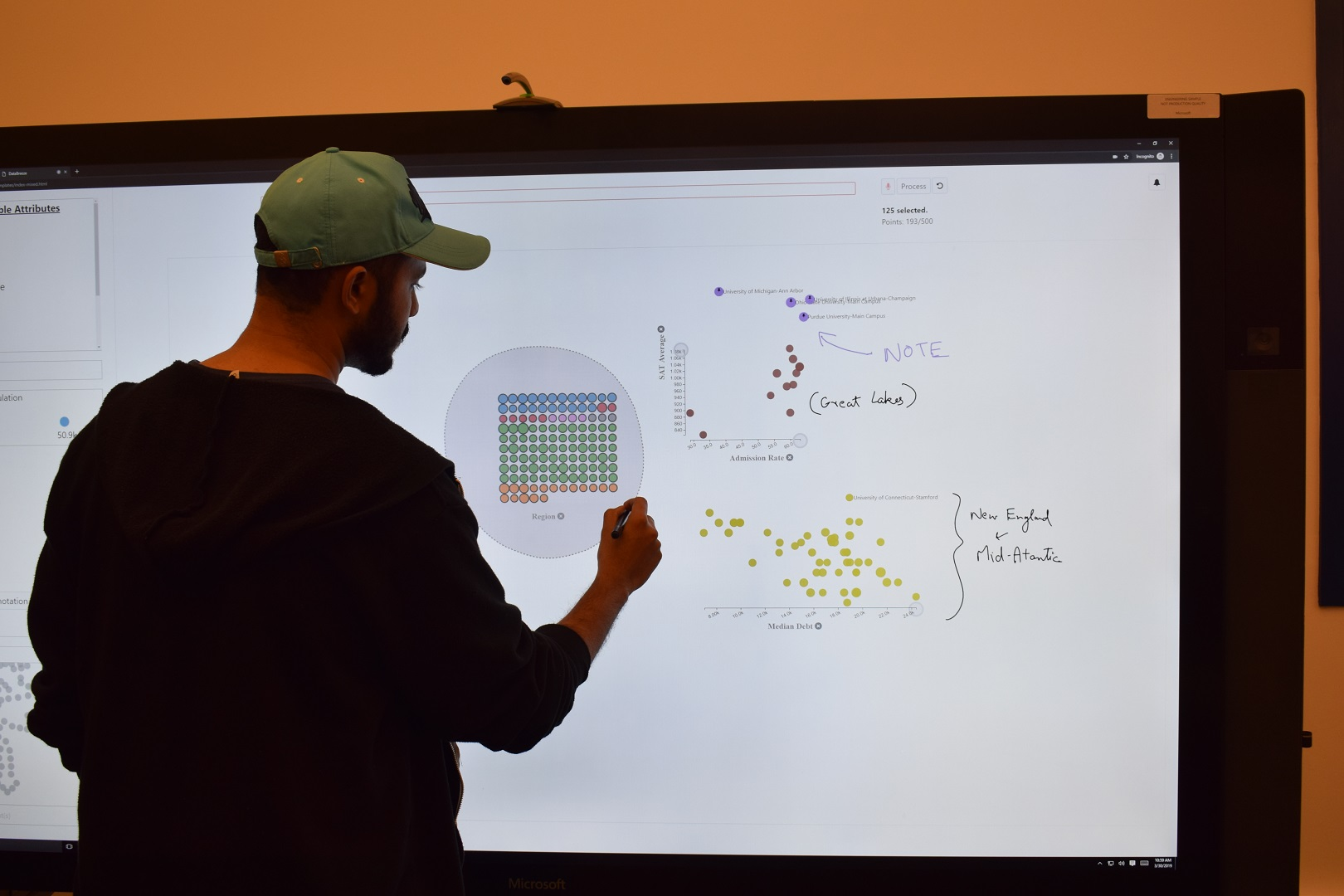
Arjun Srinivasan presented his group’s work on using multi-modal interaction (touch, pen, mouse, and voice) with unit visualizations, and presented their “DataBreeze” system (pictured above; presentation, paper, landing). They demonstrate (quite convincingly!) how a system can use multiple modalities to author and explore a dataset.
MobileVisFixer was a tool presented by Aoyu Wu on behalf of their team—the tool takes a DOM-based visualization and automatically converts it to a viewport more suited for mobile screens (presentation, paper, landing). What’s really neat about this approach is that it doesn’t necessarily require author intervention, and that it uses a reinforcement learning approach to re-scale the visualization. The methodology uses local-, global-, and relative-scales to resize elements to support summarization and reorganization of a visualization without too much loss of fidelity.
For researchers
I’ll comment a bit on the research side of things. Even if you’re not an academic, you’ll probably still get some value out of these events—they mostly concern the methods to evaluate if visualizations are effective for their intended purpose. The scope of this ranges from evaluating individual visual encoding decisions (how does it affect how fast/accurate a viewer is in obtaining the underlying data mapping?) to how visualizations fit in a workflow (do the viewers gain insights working with the visualization?).
BELIV
The BELIV workshop concentrates on the problem of evaluating visualizations and the design decisions that go into creating them. The name is a call that there better ways to evaluate a visualization than the traditional psychological methods of evaluating a visualization based on the accuracy of or time it takes a visualization viewer to answer a question about the data mapped by the visuals they see.
While the entire program was great, the second session in particular was fantastic (video link).
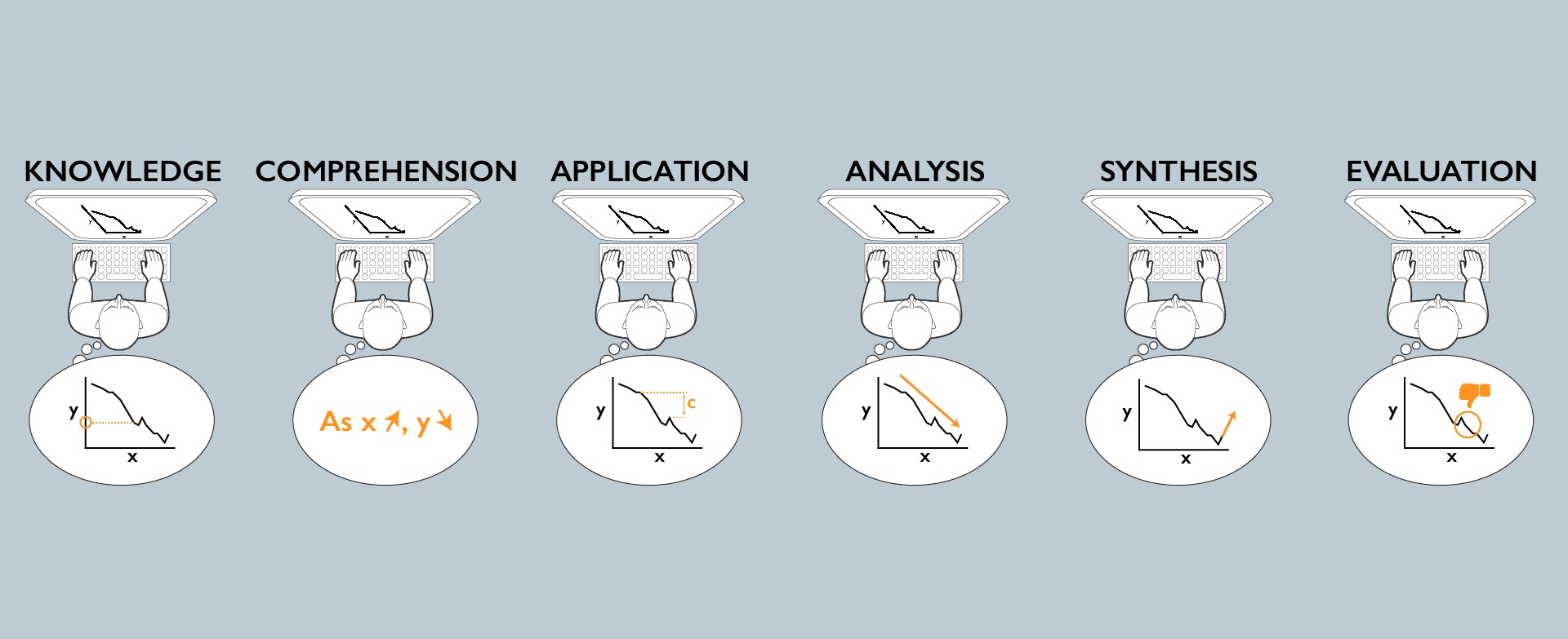
Alyx Burns talks about how to evaluate data visualizations per viewer by asking questions targeting different levels of understanding on six levels (pictured above): knowledge, comprehension, application, analysis, synthesis, and evaluation. They used these levels to distinguish two versions of the same chart in a case study in their work. More detail is available in their preprint (landing).
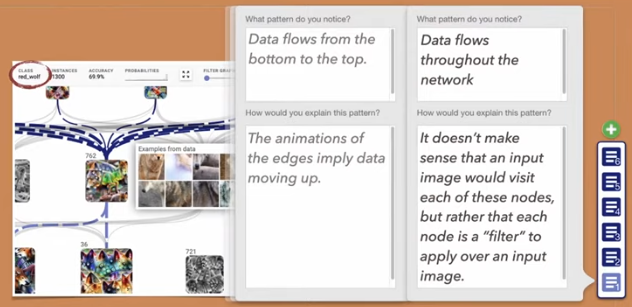
Trying to understand a viewer’s mental model of the world can help to focus a visualization based on their experiences. Jeremy Block presented a methodology they call “micro-entries” to try and evaluate a viewer’s mental model over time when engaging with an interactive data system (pictured above; presentation, paper, landing). They propose a method between “think-alouds” and “prediction” questions. This tends to take the form of small prompts that coax the viewer into self-evaluating the visualization and what they’re currently taking away from it. As they explore the system, these prompts may not change much, but the viewer’s responses may change significantly. Such a running record could help to describe the efficacy of a dynamic visualization system.
Methods for research
Ana Crisan presented fantastic work at VDS that looked at the “data science” process and how they interact with the people that use their visualization output (presentation, paper, landing). They promote the organization of high- and low-order processes and a classification of data science roles to help organize how to target both interfaces and workflows for a users’ workflow. This is moving toward the idea of user stories to drive user scenarios for visualization forward, something that I would like to explore further!
For the good of all
The InfoVis best paper award this year went to the work presented by Alex Kale focusing on strategies viewers take when viewing visualizations that communicate uncertainty (presentation, paper, landing). In the paper, they discuss different visual “shortcuts” that viewers might take as aliases to gauge their uncertainty over the data being shown in the data. The authors were particularly concerned at conveying the “right amount” of uncertainty, and their experiment design to tease this out was impressively done.
Brian Ondov presents his team’s efforts to try and understand how these aforementioned “shortcuts” (named “perceptual proxies” in this work) can mislead viewers making honest judgments from visualizations (presentations, paper, landing). They specifically use adversarial examples coupled with a stairstepping methodology to understand the effects that these proxies can have on viewer judgments. Their results provide a strong list of features to consider to ensure that visualizations are not misunderstood.
In summary
There is too much material from an IEEE VIS conference to cover in detail in a single blog post. If you are interested in this material further, I suggest you pursue the other summaries and recaps linked in the beginning of this post.
All the presentations are available on the virtual IEEE VIS 2020 website, along with DOIs for the original documents.
Acknowledgements
We consider the images used in this recap as fair use under US Copyright law (17 U.S. Code § 107) for the purpose of reporting and commentary. No images are lifted from official IEEE sources or finalized, published materials.
If you determine that there is an exception, please contact the author.